Bei der Datenmodellierung hat man nicht immer alle Aspekte vom ersten Augenblick an im Blick. Es kann passieren, dass Felder nachträglich hinzugefügt werden müssen, dass wir ihren Datentyp ändern wollen oder dass ein Tabellen- oder Feldname noch angepasst werden soll. Es kommt jedoch auch vor, dass wir Daten erst einmal in ein Textfeld schreiben und dann feststellen, dass dieses Textfeld immer wieder die gleichen Daten aufnimmt. In diesem Fall kommt es leicht dazu, dass eigentlich gleiche Werte mit unterschiedlich Schreibweise eingetragen werden. Will man nach diesen Werten filtern und gibt nur eine Schreibweise ein, erhält man nicht alle Datensätze, die man eigentlich sehen möchte. Um dies zu verhindern, kann man solche Textfelder durch Nachschlagefelder ersetzen, die ihre Werte aus Lookup-Tabellen beziehen. So sieht man bei der Eingabe direkt, dass ein Wert bereits vorhanden ist und kann diesen nutzen, statt weitere Schreibweisen hinzuzufügen. Wie wir eine solche Änderung nachträglich durchführen, zeigen wir in diesem Artikel.
Beispieldatenbank
Die Beispiele dieses Artikels findest Du in der Datenbank TabellenBasicsVomTextfeldZumLookupfeld.accdb.
Nicht ausreichende Normalisierung
In den drei Artikeln Normalisierung, Teil 1: Die erste Normalform (www.access-basics.de/498), Normalisierung, Teil 2: Die zweite Normalform (www.access-basics.de/503) und Normalisierung, Teil 3: Die dritte Normalform (www.access-basics.de/512) haben wir die ersten drei Normalformen vorgestellt, die für die meisten Fälle ausreichend sind.
Hier haben wir auch erläutert, dass alle nicht schlüsselabhängigen Attribute von funktional vom Primärschlüssel abhängen sollen.
In der Praxis bedeutet dies, dass wir redundante Daten in eine eigene Tabelle auslagern und diese dann über ein Fremdschlüsselfeld von der ursprünglichen Tabelle aus verknüpfen.
Praxisbeispiel: Bücher und Kategorien
Nehmen wir also an, wir haben in einem ersten, naiven Ansatz eine Büchertabelle entworfen, die ein Feld Kategorie enthält, in das wir den Namen der Kategorie eines jeden Buches eintragen wollen. Im Entwurf sieht die Tabelle tblBuecherMitKategorien nun wie in Bild 1 aus.
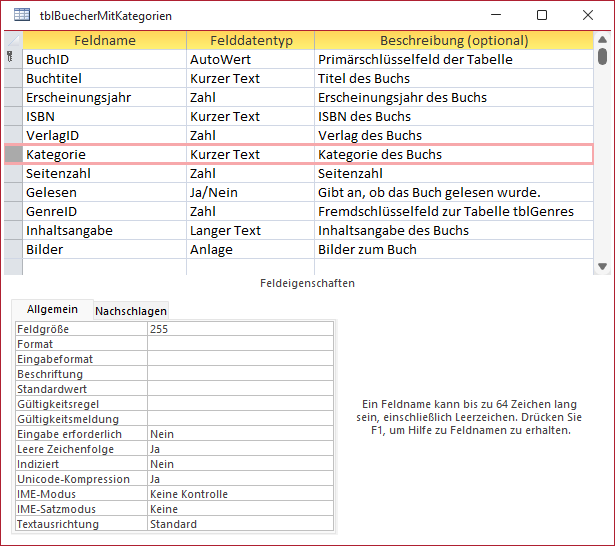
Bild 1: Entwurf der Tabelle tblBuecherMitKategorien
So weit, so gut: Wir geben ein paar Bücher ein und tragen auch fleißig die Kategorie in das jeweilige Textfeld ein. Damit sind wir sehr flexibel, denn wir können alle möglichen Kategoriebezeichnungen eintragen. Das hat allerdings einen gravierenden Nachteil: Wir können so nämlich auch alle denkbaren Schreibweisen für die Kategoriebezeichnungen hinterlegen, was der Bearbeiter der Tabelle hier bereits getan hat. So sind wie in Bild 2 bereits zwei Einträge für Kategorien vorhanden, die eigentlich das gleiche bedeuten: Fachbuch und Fachbücher.
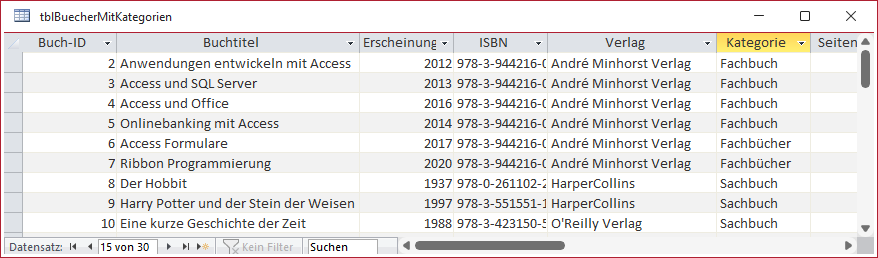
Bild 2: Die Tabelle tblBuecherMitKategorien in der Datenblattansicht
Das ist so lange kein Problem, bis ein Benutzer einmal eine Liste aller Fachbücher ausgeben möchte und sich nicht darüber bewusst ist, dass es verschiedene Schreibweisen für ein und dieselbe Kategorie gibt. Filtert er nämlich nun nach der Kategorie Fachbuch, erhält er nur die Einträge, für welche genau diese Kategoriebezeichnung hinterlegt ist, die Bücher mit der Kategorie Fachbücher fallen jedoch aus dem Suchergebnis heraus (siehe Bild 3).
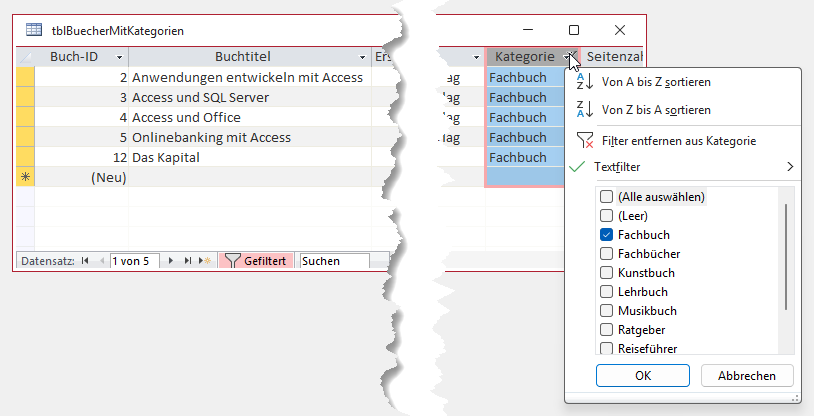
Bild 3: Das Filtern nach der Kategorie Fachbuch liefert nicht alle Fachbücher.
Solange wir die Tabelle in dieser Form beibehalten, können wir dies nicht verhindern. Gerade wenn mehr und mehr Bücher in der Tabelle landen, werden wir bald einen Wildwuchs an Kategorien angesammelt haben. Hier wird es schwierig, noch gezielt nach den Büchern einer Kategorie zu fahnden. Wir können zwar in den Filtereinstellungen mit Glück noch erkennen, dass es noch eine ganz ähnlich lautende Kategorie namens Fachbücher gibt. Da der Fantasie von Menschen aber kaum Grenzen gesetzt sind, werden früher oder später zahlreiche Varianten von Kategoriebezeichnungen in dieser Büchertabelle landen.
Also wollen wir geeignete Maßnahmen nutzen, um dies zu verhindern. Aber wie sollen diese aussehen
Bei der Eingabe gäbe es Möglichkeiten – mittlerweile kann man schon KI per VBA aufrufen und bei der Eingabe prüfen, ob bereits eine ähnlich lautende Kategoriebezeichnung vorhanden ist.
Aber wie eingangs erwähnt, wollen wir ohnehin den Normalformen folgen und das Datenmodell in einen Zustand bringen, in dem Informationen gleichen Typs auch in jeweils einer eigenen Tabelle landen und gegebenenfalls verknüpft werden.
Normalisierung für Kategorien
Im Falle unserer Tabelle, die gleichzeitig Informationen über Büchern und Kategorien enthält, gehen wir daher wie folgt vor:
- Wir erstellen eine Tabelle namens tblKategorien, in der wir die Kategorien für die Bücher hinterlegen wollen. Wir könnten diese sogar auch tblBuchkategorien nennen, wenn abzusehen ist, dass es in der Datenbank noch weitere Kategorien für andere Elemente geben wird. In diesem Fall belassen wir es jedoch bei der Bezeichnung tblKategorien.
- Dann fügen wir der Tabelle tblBuecher ein Nachschlagefeld hinzu, mit dem wir die Datensätze der tabelle tblKategorien auswählen können.
Anschließend folgen die notwendigen Anpassungen der Daten:
Unser exklusives Angebot für Dich!
(Das Abo ist jederzeit monatlich kündbar)
Hier geht’s weiter →Die ersten 4 Wochen kostenlos testen – voller Zugriff auf alle Artikel, vollständigen Code und Beispieldatenbanken. Kein Risiko: Wenn es nicht passt, kündigst Du einfach innerhalb der ersten vier Wochen.
Oder hast Du eine konkrete Frage zu Deiner eigenen Access-Anwendung?
Vielleicht stellt Deine Anwendung Dich vor eine Herausforderung, zu der Du bisher keine Lösung findest. Schlechte Performance, kein ausreichender Zugriffsschutz, Du bist unsicher über Dein Datenmodell oder Dein Code liefert unerklärliche Fehler?
In unserem kostenlosen Access-Audit schaut sich André Minhorst persönlich gemeinsam mit Dir Deine Lösung per Zoom an – und zeigt Dir, wo Datenmodell, VBA-Code, Ergonomie und Sicherheit Optimierungspotenzial bieten.
Jetzt kostenloses Access-Audit anfordern →