Der Entwurf eines Datenmodells und der darin enthaltenen Tabellen und Beziehungen erfordert vor allem eines: Das Berücksichtigen der Normalformen. Dies sind Regeln, mit denen Sie die benötigten Felder auf verschiedene Tabellen aufteilen. Dabei ist das Ziel, redundante Daten auszuschließen und Inkonsistenzen zu verhindern. Diese Artikelreihe beschreibt die wichtigsten Normalformen und wie Sie diese in der Praxis anwenden.
Beispieldatenbank
Die Beispiele dieses Artikels finden Sie in der Datenbank 2006_Normalisierung.accdb.
Ausgangssituation
Im ersten Teil der Artikelreihe haben wir die erste Normalform betrachtet, die besagt, dass jedes Feld atomare Informationen enthalten soll. Dabei haben wir Daten zweier Felder, die Straße und Hausnummer sowie PLZ und Ort enthielten, auf jeweils zwei neue Felder aufgeteilt.
Die neue Tabelle enthält Projekt- und Kundendaten und sieht wie in Bild 1 aus. An dieser Stelle setzen wir die Normalisierung fort und schauen uns die zweite Normalform an.
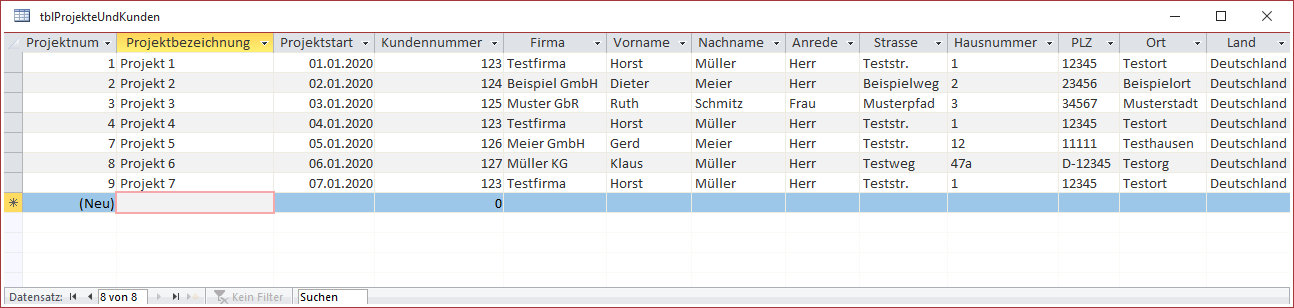
Bild 1: Zu normalisierende Daten
Die zweite Normalform
Die Definition auf Wikipedia für die zweite Normalform lautet:
„Eine Relation ist genau dann in der zweiten Normalform, wenn die erste Normalform vorliegt und kein Nichtprimärattribut (Attribut, das nicht Teil eines Schlüsselkandidaten ist) funktional von einer echten Teilmenge eines Schlüsselkandidaten abhängt.“
Bezogen auf die Tabelle tblProjekteKunden bedeutet dies Folgendes: Die Tabelle besitzt prinzipiell einen aus den beiden Feldern Projektnummer und Kundennummer zusammengesetzten Primärschlüssel. Eine Teilmenge wäre also eines der beiden Felder Projektnummer und Kundennummer. Und es gibt Felder, die von Projektnummer abhängig sind (Projektbezeichnung, Projektstart) und Felder, die von Kundennummer abhängig sind (die übrigen Felder).
Unsere Tabelle ist also nicht in der zweiten Normalform. Das wäre nur der Fall, wenn alle Nicht-Primärschlüsselfelder von den zum Primärschlüssel zusammengesetzten Feldern abhängig wären. Das ist etwa in einer Bestellpositionen-Tabelle der Fall, die einen aus den beiden Feldern BestellungID und ArtikelID zusammengesetzten Primärschlüssel enthält – dort sind alle weiteren Felder von diesem Primärschlüssel abhängig.
Praktische Aspekte der zweiten Normalform
Schauen wir uns die Tabelle tblProjekteUndKunden nochmal genauer an. Der erste, vierte und siebte Datensatz enthalten Projekte mit dem gleichen Kunden. Legen Sie hier nun für ein neues Projekt mit diesem Kunden die Firma Test-Firma statt Testfirma an, finden Sie bei einer Suche nach Testfirma nicht mehr alle Projekte zu diesem Kunden.
Die redundanten Daten führen leicht zu Inkonsistenzen, und das wollen wir vermeiden.
Diese wollen wir nun so aufteilen, dass die Projekte und die Kunden in je einer eigenen Tabelle namens tblProjekte und tblKunden landen. Beide Tabellen benötigen ein eigenes Primärschlüsselfeld. Die Daten dafür liegen uns bereits vor: Die Tabelle tblProjekte verwendet das Feld Projektnummer als Primärschlüsselfeld, die Tabelle tblKunden das Feld Kundennummer.
Danach müssen wir allerdings noch die Zuordnung zwischen den Kunden und Projekten sicherstellen. Weisen wir ein Projekt einem Kunden zu oder einen Kunden einem Projekt Letzteres ist der Fall, und damit wissen wir, dass wir der Tabelle tblProjekte ein Fremdschlüsselfeld hinzufügen müssen, mit dem wir den Eintrag der Tabelle tblKunden festlegen, für den das Projekt durchgeführt werden soll.
Aufteilung der Tabelle tblProjekteUndKunden
Die Tabelle tblProjekteUndKunden wollen wir nun wie in Bild 2 auf die beiden Tabellen tblProjekte und tblKunden aufteilen. Dazu erstellen wir die beiden Zieltabellen, wobei wir die Felder Projektnummer und Kundennummer gleich durch die in diesem Magazin üblichen Bezeichnungen ProjektID und KundeID ändern. Die beiden Primärschlüsselfelder müssen Sie direkt als Autowert festlegen, da sich dies nicht mehr einstellen lässt, wenn Sie einmal Daten in die Tabelle geschrieben haben.
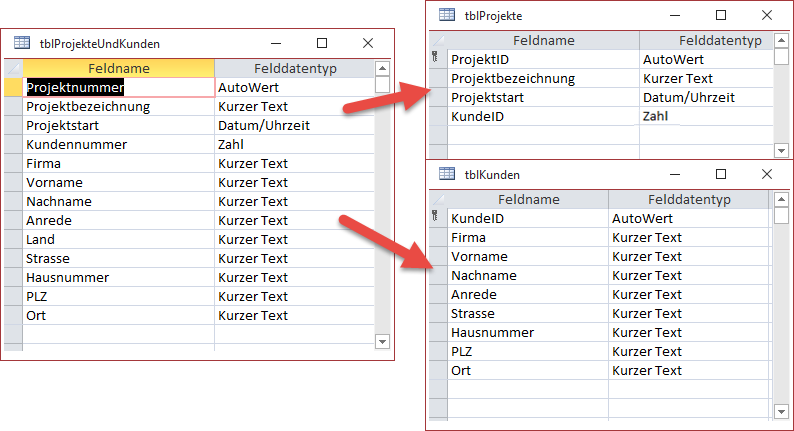
Bild 2: Aufteilung der Tabelle tblProjekteUndKunden
Der Tabelle tblProjekte fügen wir außerdem gleich das Fremdschlüsselfeld KundeID mit dem Datentyp Zahl hinzu.
Nun benötigen wir noch halbwegs automatische Möglichkeiten, um die Daten der Tabellen aufzuteilen. Dies erledigen wir in zwei Schritten:
- Hinzufügen der Kundendaten zur Tabelle tblKunden
- Hinzufügen der Projektdaten zur Tabelle tblProjekte
Kundentabelle füllen
Den ersten Schritt erledigen wir mit einer Anfügeabfrage. Dazu erstellen Sie eine neue Abfrage und ändern den Abfragetyp über den Ribbon-Eintrag Entwurf|Abfragetyp|Anfügen. Nun erscheint der Dialog Anfügen, mit dem Sie die Zieltabelle auswählen, hier tblKunden (siehe Bild 3).
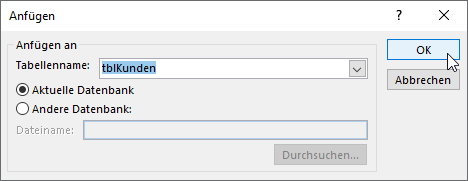
Bild 3: Auswählen der Zieltabelle für die Anfügeabfrage
Danach bearbeiten Sie den Entwurf der neuen Anfügeabfrage. Fügen Sie die Tabelle tblProjekteUndKunden zum Entwurf hinzu und ziehen Sie die Felder für die Kunden in das Entwurfsraster. Access ordnet Felder gleichen Namens automatisch zu, sodass wir nur noch das Feld KundeID als Ziel für das Feld Kundennummer auswählen müssen (siehe Bild 4).
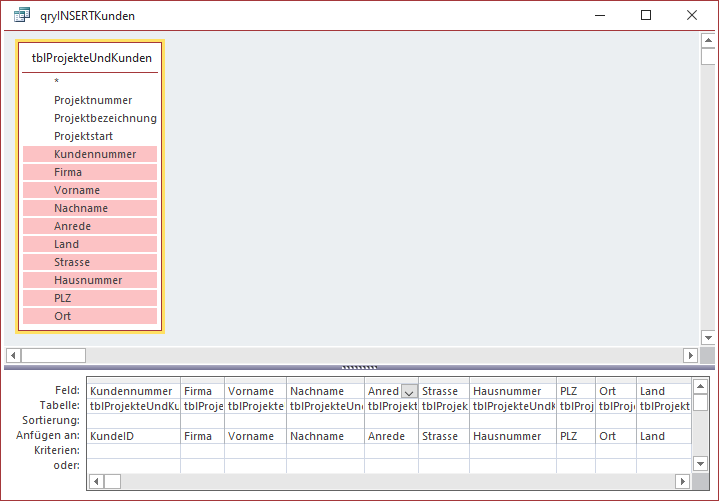
Bild 4: Anfügeabfrage zum Füllen der Tabelle tblKunden
Unser exklusives Angebot für Dich!
(Das Abo ist jederzeit monatlich kündbar)
Hier geht’s weiter →Die ersten 4 Wochen kostenlos testen – voller Zugriff auf alle Artikel, vollständigen Code und Beispieldatenbanken. Kein Risiko: Wenn es nicht passt, kündigst Du einfach innerhalb der ersten vier Wochen.
Oder hast Du eine konkrete Frage zu Deiner eigenen Access-Anwendung?
Vielleicht stellt Deine Anwendung Dich vor eine Herausforderung, zu der Du bisher keine Lösung findest. Schlechte Performance, kein ausreichender Zugriffsschutz, Du bist unsicher über Dein Datenmodell oder Dein Code liefert unerklärliche Fehler?
In unserem kostenlosen Access-Audit schaut sich André Minhorst persönlich gemeinsam mit Dir Deine Lösung per Zoom an – und zeigt Dir, wo Datenmodell, VBA-Code, Ergonomie und Sicherheit Optimierungspotenzial bieten.
Jetzt kostenloses Access-Audit anfordern →