Lies diesen Artikel und viele weitere mit einem kostenlosen, einwöchigen Testzugang.
Der geradezu prototypische Anwendungsfall für eine Datenbank ist sicherlich die Speicherung von Kontakten. Ob Nordwind-, unsere Südwinddatenbank oder die hier oft verwendete Stammdatentabelle: im Zentrum stehen Adressdatensätze. Auf den ersten Blick gibt es dabei keinen Erklärungsnotstand, denn so ein Kontaktdatensatz scheint eine einfache Angelegenheit zu sein. Bei genauerem Hinsehen tauchen aber doch Fragen auf, die dieser Beitrag thematisiert.
Beispieldatenbank
Die Beispiele dieses Artikels finden Sie in der Datenbank 1411_Adressen.mdb.
Für die Beispieldatenbank zu diesem Beitrag wurde die Stammdatentabelle aufgebohrt und mit zusätzlichen Feldern und Daten versehen. Neben Namen und Anschrift kommen Telefonnummern und E-Mail-Adressen hinzu, so dass sie sich wie in Bild 1 gestaltet. In diese Tabelle könnten Sie bereits etwa Ihre Outlook-Kontakte importieren.
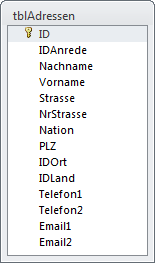
Bild 1: Aufbau der Adressentabelle
Man findet Adresstabellen in dieser Form recht häufig in Datenbanken. Dabei ist der Aufbau keineswegs optimal, obwohl es sich bereits um eine normalisiertere Form handelt, denn Anreden, Orte und Länder sind bereits mit Lookup-Tabellen verknüpft (siehe Bild 2).
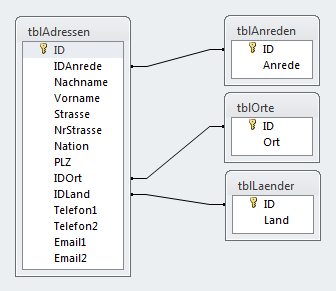
Bild 2: Lookup-Tabellen der Adressentabelle
Diese Felder verhindern auch einen einfachen Import aus anderen Datenquellen. Damit etwa im Feld IDOrt der Bezug zur Tabelle tblOrte gespeichert werden kann, muss diese erst mit Orten gefüllt worden sein. Natürlich könnte man diese Felder auch als Text anlegen, was in Hinsicht auf den Speicherbedarf jedoch suboptimal ist. Beim Import aus anderen Datenquellen kommt es in der Regel jedoch zu so einer Tabelle, die in der Beispieldatenbank als tblAdressenImport zu finden ist (Bild 3).
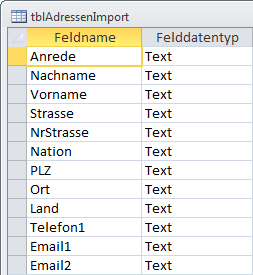
Bild 3: Aufbau der Importtabelle
Normalisieren des Imports
Im Folgenden wird Schritt für Schritt aufgezeigt, wie die Importtabelle in eine normalisierte Form überführt wird.
Legen Sie also zunächst die Lookup-Tabellen rechts in Bild 2 an, wobei für das Feld ID ein Autowert als Primärschlüssel zu verwenden ist und für das andere Feld – Anrede, Ort, Land – das Textformat. Jetzt kann die Tabelle tblOrte mit Daten gefüllt werden, wofür eine Anfügeabfrage zum Einsatz kommt:
INSERT INTO tblOrte (Ort) SELECT DISTINCT Ort FROM tblAdressenImport;
Nur die Orte der Ausgangstabelle werden hier in die Orte-Tabelle gespeichert, wobei Doppelungen infolge der DISTINCT-Klausel ausbleiben. Analog die Anfügeabfragen für die Länder und Anreden:
INSERT INTO tblLaender (Land) SELECT DISTINCT Land FROM tblAdressenImport; INSERT INTO tblAnreden (Anrede) SELECT DISTINCT Anrede FROM tblAdressenImport;
Sehen Sie sich die Inhalte der Tabellen an. Hier wird schon deutlich, worin der Vorteil der Normalisierung liegt. Waren in der Importtabelle noch 11.444 Felder mit Länderbezeichnungen gefüllt, sind es in der Ländertabelle nur noch 16 Einträge, auf die per ID verwiesen werden muss. Und da der Long-Wert von IDLand weniger Bytes benötigt, als ein Bezeichnungs-String, wird die Speicherersparnis offensichtlich.
Diese Rechnung zeigt allerdings, dass nicht in jedem Fall eine solche Normalisierung nützlich ist. Nehmen Sie etwa das Feld Nation der Importtabelle. Auch hier könnte man eine Lookup-Tabelle tblNationen anlegen, die dann lediglich die zwei Einträge „D“ und „CH“ für Deutschland und Schweiz enthielte.
Ende des frei verfügbaren Teil. Wenn Du mehr lesen möchtest, hole Dir ...
Testzugang
eine Woche kostenlosen Zugriff auf diesen und mehr als 1.000 weitere Artikel
diesen und alle anderen Artikel mit dem Jahresabo