Auch wenn die Assistenten von Access zum Import und Export von Textdateien über ihre Einstellungsseiten genügend Möglichkeiten bieten, um mit allen erdenklichen Formaten zurechtzukommen, gibt es häufig Situationen, in denen die Verarbeitung über VBA-Programmierung benötigt wird. Hier geht es in erster Linie um den Umgang mit Texten in unterschiedlicher Sprachkodierung.
Beispieldatenbank
Die Beispiele dieses Artikels finden Sie in der Datenbank 1503_Textumwandlung.mdb.
Sprachen, Codepages, CharacterSets
Beleuchten wird zunächst, was es mit den Sprachcharakteristiken von Textdateien auf sich hat. Wenn Sie sich eingehender mit Textformaten beschäftigen – Stichwort Internationalisierung -, so begegnen Sie immer wieder Begriffen, wie Language Id, Locale Identifier (LCID), Codepage, Unicode und Character Set. Jeder hat seine eigene Bedeutung und doch hängen alle irgendwie miteinander zusammen. Grundsätzlich geht es dabei nicht nur um Textdateien, sondern generell um den Umgang mit Texten im System. Betroffen sind damit etwa die Tastatur, die Textausgabe auf dem Bildschirm, Schriftarten, oder auch die Interaktion mit dem Internet.
An oberster Stelle steht die Sprache eines Textes, die wiederum einer Gruppe von Sprachen angehören kann. Deutsch etwa gehört zur Gruppe Westeuropa und USA. Windows unterstützt von Haus aus mehrere Sprachgruppen und Sprachen. Dabei gibt es einen Unterschied zwischen nur unterstützten und den installierten Sprachen. Während es genau 17 Gruppen gibt, kann die Zahl der zugehörigen Sprachen selbst variieren. Für den Umgang mit Texten ist die Gruppierung weniger interessant, denn sie betrifft vor allem die Tastaturbelegung, die in der Regel pro Sprachgruppe eindeutig ist.
Welche Sprachen Windows unterstützt können Sie mit einem Doppelklick auf die Tabelle tblLCIDs der Beispieldatenbank herausfinden (siehe Bild 1). In der zweiten Spalte finden Sie die Sprache, in der dritten das zugehörige Land. Auf die Bedeutung der vierten (CP) kommen wir noch zu sprechen. Das Feld LCID legt die eindeutige Id der Sprache fest. Diese Zahl werden Sie häufiger unter Windows finden. Schauen Sie etwa in den Order von Microsoft Office im Explorer zu Ihrer Office-Version. Dort werden Sie als Unterverzeichnisse die von Ihrem Office unterstützten Sprachen als LCID finden. Die 1033 für Englisch (USA) ist immer mit dabei, die 1031 für Deutsch wahrscheinlich auch. In diesen Verzeichnissen befinden sprachspezifische Ressourcen für Office. Installieren Sie etwa zusätzlich die Rechtschreibprüfung für Französisch, so entsteht hier ein weiterer Ordner mit dem Namen 1036.
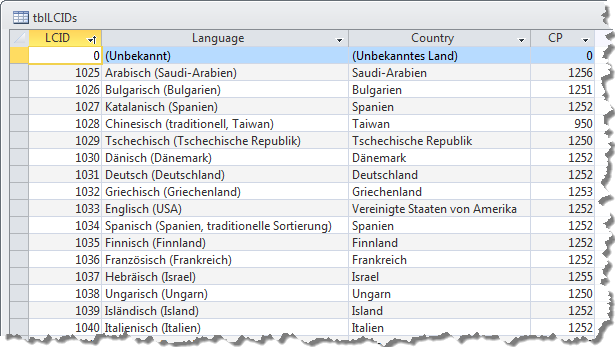
Bild 1: Inhalt der Tabelle tblLCIDs mit den von Windows unterstützten Sprachen
Ist die Sprache mit ihrer LCID noch eindeutig, so ist es das Land nicht. Filtern Sie die Tabelle nach dem Land Deutschland, so ergeben sich vier Datensätze, unter denen sich etwa auch das sehr spezielle Niedersorbisch befindet.
Der Inhalt dieser Tabelle ist keineswegs in Stein gemeißelt. Je nach Windows-Version, -Installationsoptionen und -Sprache kann sie andere Datensätze aufweisen. Sie können die Tabelle auf Ihrem System selbst erstellen. Dazu gibt es im VBA-Modul mdlTextconverter der Beispieldatenbank eine Prozedur EnumLanguageGroupsLocales. die Sie aus dem Direktfenster des VBA-Editors heraus aufrufen können. Sie löscht zunächst den Inhalt der Tabelle und erstellt ihn dann über verschiedene API-Funktionen neu. Es gibt allerdings keine API-Funktion, die die Sprachen direkt aufzählen könnte. Erst müssen die einzelnen Sprachgruppen ermittelt (EnumLanguageGroups), in einer Collection zwischengespeichert und anschließend der Sprach-Enumeration übergeben werden. In Listing 1 sehen Sie den Code der Prozedur, der hier nur exemplarisch angeführt wird.
Sub EnumLanguageGroupsLocales() Dim vID As Variant Set colInfo = New VBA.Collection CurrentDb.Execute "DELETE FROM tblLCIDs" CurrentDb.Execute "INSERT INTO tblLCIDs(LCID,Language,Country,CP) " & _ "VALUES (0,'(Unbekannt)','(Unbekanntes Land)',0)" EnumLanguageGroups For Each vID In colInfo EnumLanguageGroupLocales AddrOf(AddressOf LanguageGroupLocalesProc), _ ByVal CLng(Val("&H" & vID)), ByVal 0&, 0& Next vID End Sub
Listing 1: Prozedur zum Füllen der Tabelle tblLCIDs mit Sprachdatensätzen
Denn im Rahmen dieses Beitrags würde es eindeutig zu weit führen, die nicht unkomplizierten und mit API-Aufrufen gespickten Funktionen näher zu erläutern. Und ohne API-Funktionen kommt man allein mit den Bordmitteln der VBA-, Access- und Office-Bibliotheken bei diesem Thema nicht weiter.
Kommen wir zu der vierten Spalte der Tabelle mit dem Namen CP, was ein Kürzel für Codepage darstellt. Dort ist zu jeder Sprache die Vorgabe-Codepage zu finden. Was aber ist eine Codepage Dazu ein Ausflug in die binäre Speicherung von Texten: Für jedes Zeichen wird bei Single-Byte-Formaten (ANSI, OEM) genau ein Byte festgelegt. Schreiben Sie ein A in einen Text, so finden Sie unter einem Hex-Editor an dieser Stelle die Zahl 65. Genauso gut können Sie auch VBA bemühen:
Asc ("A") -> 65
Chr (65) -> "A"
Die 65 kennzeichnet, welches Zeichen innerhalb der deutschen Sprach-Codepage zu finden ist. Eine Codepage ist damit imgrunde eine Tabelle mit 255 Datensätzen, die jeder Position ein bestimmtes Zeichen zuordnet. Und eben diese Position ist, je nach Sprache, unterschiedlich. So ermitteln Sie etwa für ein ü den Code 220. In Russland aber kennt man kein ü. Die dort verwendete Codepage ordnet der 220 ein anderes, ein kyrillisches Zeichen zu. Ein Text in deutscher Sprache mit Umlauten wird dort falsch dargestellt, wenn er mit dem russischen Notepad geöffnet wird. Ein russisches Word hingegen wird beim öffnen der Textdatei nachfragen, welche Codepage zu verwenden ist, und erst nach Einstellung von Westeuropa (Windows) das korrekte Ergebnis zeitigen.
Die Codepage ist also die zentrale Schaltstelle, wenn es um Textverarbeitung geht. Erst sie ermöglicht es, einem Byte-Code ein bestimmtes Zeichen zuzuordnen.
Nun braucht es nicht für jede einzelne Sprache eine gesondert Codepage. Die ANSI–Codepage für Westeuropa (1252) etwa kennt fast alle benötigten Zeichen für die Sprachen Europas, also die deutschen Umlaute und die französischen oder spanischen Akzente.
Es ist demnach ökonomischer, mehreren Sprachen eine Codepage zuzuweisen. So steht in der CP-Spalte der Sprachtabelle für Deutsch, Italienisch, Französisch, Spanisch, Englisch überall die 1252. Filtern Sie die Tabelle nach diesem Wert: Erstaunlicherweise gibt es über Hundert Sprachen, die sich diese Codepage teilen.
Nun kann man sich eine Zahl als Bezeichner für eine Codepage nur schwer merken. Deshalb haben Codepages auch Namen. öffnen Sie die Tabelle tblCodepages der Beispieldatenbank (siehe Bild 2). Sie finden dort unter dem Feld Description die Bezeichnungen der Codepages. Die 1251 nennt sich exakt ANSI – Lateinisch I. Das ist gut zu wissen, denn eine Bezeichnung mit dem Teilinhalt Westeuropa werden Sie nämlich vergeblich suchen.
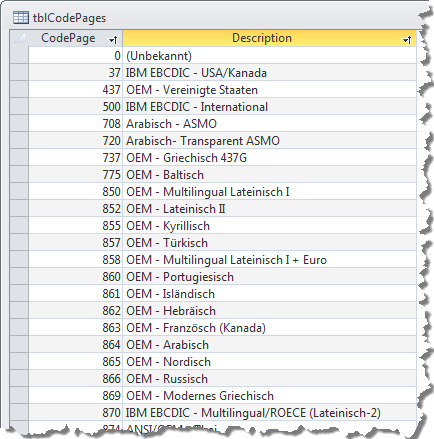
Bild 2: Inhalt der Tabelle tblCodepages
In der Tabelle sind allerlei kryptische Codepages aufgeführt, die zum großen Teil veraltet und nicht mehr in Gebrauch sind.
Sie werden sie unter Umständen dennoch benötigt, wenn Sie es mit Textdateien zu tun haben, die aus IT-Urzeiten stammen, wie die IBM-Codes. Eher noch treffen Sie auf Texte von MS-DOS-Systemen, die in der Tabelle durch das Präfix OEM gekennzeichnet sind.
Es gibt überdies ein Problem mit diesen Bezeichnungen, die leider nicht so eindeutig sind. Die Bezeichnungen in der Tabelle sind das Resultat einer Windows-API-Funktion, die in der Prozedur GetCPName der Beispieldatenbank zum Einsatz kommt:
GetCPName (1252) - > "(ANSI - Lateinisch I)"
Mithilfe dieser Prozedur und derjenigen zum Auflisten der Codepages (EnumCodepages), aufgerufen aus dem VBA-Direktfenster, können Sie den Inhalt der Tabelle neu erstellen. Wie wir noch sehen werden, gibt es aber auch noch die Möglichkeit, sich über DAO und die Access Database Engine alle Codepages ausgeben zu lassen. Dieses Ergebnis gibt die Tabelle tblCodepagesDAO wieder. Und dort steht für die Codepage 1252 die Bezeichnung Westeuropäisch (Windows). Damit Sie alle Sprachen, die zugehörigen Default-Codepages und deren Bezeichnungen im Blick haben, fasst die Abfrage qry_LCID_CP die drei besprochenen Tabellen zusammen und gibt sie wie in Bild 3 wieder. Sie sollte genügen, um aus einer Bezeichnung die zugehörige Codepage zu identifizieren. Denn diese Bezeichnungen listen etwa die Kombinationsfelder von Access oder Word auf, wenn es um die Auswahl einer Codepage geht.
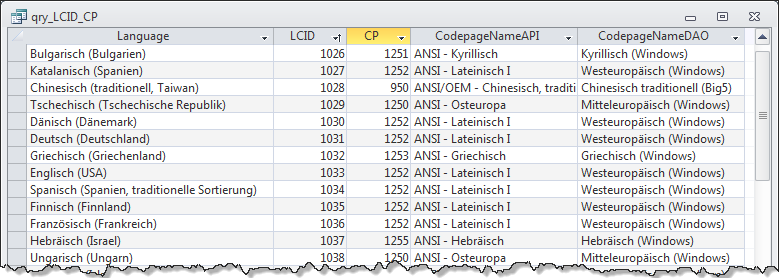
Bild 3: Alle Sprachen und deren Codepages gibt die Abfrage qry_LCID_CP aus
Zuletzt fehlt noch die Erläuterung des Begriffs Character Set, zu Deutsch Zeichensatz. Die Zuordnung der Bytes eines Textes zu bestimmten Zeichen über die Codepage ist das Eine, die visuelle Darstellung dieses Zeichens über Schriften das Andere. Eine Schriftart kann mit der Codepage allein noch nichts anfangen. Der Satz von darstellbaren Zeichen ist durch den Zeichensatz definiert. Die wiederum ist ebenfalls über eine bestimmte Nummer gekennzeichnet. Die Funktion CharSetFromCP der Beispieldatenbank nimmt als Parameter eine Codepage entgegen und gibt die ID des zugehörigen Zeichensatzes zurück:
Unser exklusives Angebot für Dich!
(Das Abo ist jederzeit monatlich kündbar)
Hier geht’s weiter →Die ersten 4 Wochen kostenlos testen – voller Zugriff auf alle Artikel, vollständigen Code und Beispieldatenbanken. Kein Risiko: Wenn es nicht passt, kündigst Du einfach innerhalb der ersten vier Wochen.
Oder hast Du eine konkrete Frage zu Deiner eigenen Access-Anwendung?
Vielleicht stellt Deine Anwendung Dich vor eine Herausforderung, zu der Du bisher keine Lösung findest. Schlechte Performance, kein ausreichender Zugriffsschutz, Du bist unsicher über Dein Datenmodell oder Dein Code liefert unerklärliche Fehler?
In unserem kostenlosen Access-Audit schaut sich André Minhorst persönlich gemeinsam mit Dir Deine Lösung per Zoom an – und zeigt Dir, wo Datenmodell, VBA-Code, Ergonomie und Sicherheit Optimierungspotenzial bieten.
Jetzt kostenloses Access-Audit anfordern →